
Building privacy-first AI tools: lessons from scientific communication
You’re developing a 200-slide training deck for global rollout. Your inputs include slides from the US team (who abbreviate everything), content from European colleagues (who spell everything out), and “core slides” from global (each with different reference formatting). Even more challenging: materials that cite drafts of clinical study reports and pre-print manuscripts before they were reviewed and proofread, meaning there are likely mistakes in the slides that need to be corrected. As you build each section, you need to harmonize these disparate sources while ensuring abbreviations stay consistent, references follow your MLR team’s exact requirements, and every visual asset maintains quality standards. Multiply this challenge across many team members, regions, and versions, and the complexity becomes overwhelming. Purpose-built AI tools in scientific communication address exactly this kind of problem. The goal isn’t to catch problems at review—it’s to transform chaotic inputs into cohesive, compliant materials from the start.
The mainstream AI revolution has largely bypassed scientific content creation in our industry, and for good reason. When handling competitively sensitive information such as unpublished clinical trial data and other data on file, teams can’t simply upload files to ChatGPT—doing so risks exposing confidential information that could be stored, processed by third parties, or potentially used to train future models. Yet the efficiency gains AI offers are too significant to ignore. This gap between what’s available and what’s actually usable in scientific communication creates an opportunity to explore purpose-built solutions.
The privacy paradox in scientific communication
The challenge isn’t whether AI can help—it clearly can. The challenge is making AI work within the constraints of medical affairs and medical training. Every tool must balance three critical requirements: efficiency, accuracy, and security. Drop any one of these, and the tool becomes a liability.
Most generic AI solutions fail on security. They require uploading sensitive materials to external servers. They are trained on user data. And they lack the audit trails MLR teams require. This reality has led to a different approach: building purpose-specific tools that process data entirely locally or through carefully selected non-training models, depending on security requirements and specific use cases.
Learning from tool building: practical applications
The exploration of AI tool building often begins with simple questions: “why are we manually checking 500 references?” or “why are we spending so much time writing abbreviation lists? ” The answer—”because no secure tool exists”—reveals opportunities to explore what purpose-built AI can achieve.
Reference management insights
When agencies receive 15 publications along with 50 slides from the US team, 30 from Europe, and core slides from global—each with different citation styles—manual standardization becomes a herculean task. An effective reference formatting tool can transform any citation format in a deck: italicizing journal names consistently, standardizing author formats, and expanding page numbers uniformly. What once meant hours of manual reformatting across hundreds of citations can take minutes.
Understanding abbreviation complexity
Different regions have different preferences, older documents may use outdated terms, and when teams copy content from existing presentations, they can inherit years of accumulated inconsistencies or errors. Abbreviation finder tools can automatically extract and analyze all abbreviations, recognizing variations humans often miss: “TNF” vs “TNF-α” vs “TNF-alpha.”
Consider this scenario: a training program built from materials spanning five years and three regions contained seven different variations for the same three core concepts. When identified during initial development, immediate standardization became possible—creating professional materials that are easier for the target audience to follow. Additionally, in training materials, this consistency helps the team align on the organization’s preferred nomenclature and conventions, so employees simultaneously learn both content and style.
Rapid concept visualization: transforming the creative process
Perhaps the most transformative application addresses the need for quick visual concepts during strategy development. Traditional workflows require briefing designers, waiting for drafts, multiple revision rounds—all before knowing if the concept will work.
In one case, a team using local AI running entirely on secure servers generated storyboard sketches, concept visuals, and a voice-over script for a series of 7 videos about diagnosing a rare disease. The first draft took hours instead of days. Of course, experienced medical content developers still needed to confirm that terms were used consistently, facts were checked, and client feedback was addressed. But the entire process—from concept to approved materials—was completed 40% faster than traditional workflows.
This approach doesn’t replace medical illustrators—it accelerates the concept phase so validated concepts are ready when design professionals get involved. The security aspect remains crucial: sensitive pre-launch data can be explored without incurring additional risk from AI tools.
Selecting appropriate privacy models
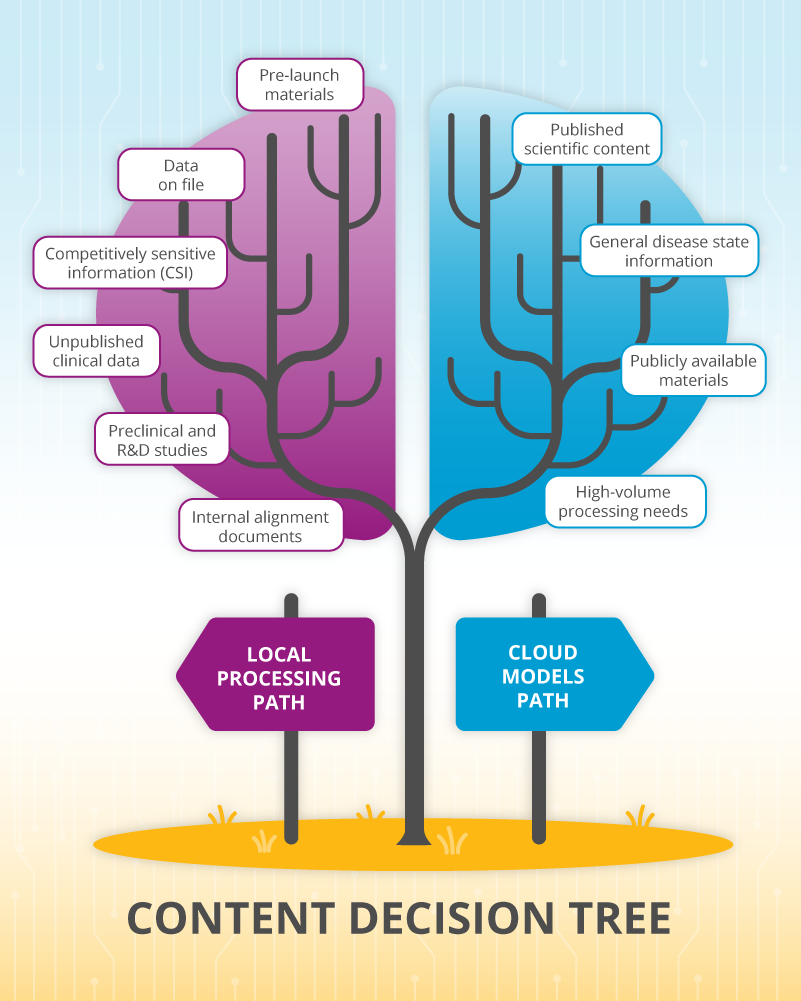
Not all content requires the same level of security, and AI tools should offer appropriate options.
Local processing is essential for:
- Pre-launch materials
- Data on file
- Competitively sensitive information (CSI)
- Unpublished clinical data
- Preclinical and R&D studies
Non-training cloud models work well for:
- Published scientific content
- General disease state information
- Publicly available materials
- High-volume processing needs
This flexibility allows teams to balance security requirements with intelligence and processing efficiency while always maintaining control over their data.
Key principles for AI in scientific communication
As the industry continues exploring AI applications, certain principles emerge as essential:
Augmentation, not replacement: AI handles repetitive tasks while humans provide scientific judgment and creative vision.
Privacy by design: Every tool should start with security requirements. Local processing for confidential materials, non-training cloud models for published content.
Industry-specific solutions: Generic tools retrofitted for pharma will always fall short of purpose-built solutions that understand industry requirements, from LMR compliance and medical communication conventions to audience-appropriate messaging that avoids promotional claims in non-promotional materials.
Continuous improvement: LMR preferences and user experiences should drive tool refinement, creating better workflows for everyone involved.
The question isn’t whether AI will transform scientific communication—it’s how to harness its power while maintaining security, accuracy, and compliance. By building purpose-specific tools, the industry can create practical solutions that address real workflow challenges. The efficiency gains are measurable, but the true impact lies in freeing teams to focus on what matters: crafting compelling visual narratives that make complex medical science accessible to those who need it.